Recently I wrote a script to pull the cloudwatch metrics (including the custom ones – Memory utilization) using CLI. Objective is to have have the data published to S3 and then using Athena/QuickSight, create a dashboard so as to have a consolidated view of all the servers across All the AWS accounts for CPU and Memory utilization.
This dashboard will help to take a right decision on resizing the instances thereby optimizing the overall cost.
Script is scheduled (using crontab) to run every one hour. There are 2 parts of the script
1. collect_cw_metrics.py – This is the main script
2. collect_cw_metrics.sh – This is a wrapper and internally calls python script.
How the script is called :
/path/collect_cw_metrics.sh <Destination_AWS_Account ID> <S3_Bucket_AWS_Account_ID> [<AWS_Region>]
Wrapper script – collect_cw_metrics.sh
#!/bin/sh
if [[ $# -lt 2 ]]; then
echo "Usage: ${0} <AccountID> <S3_Bucket_AccountID>"
exit 1
fi
NOW=$(date +"%m%d%Y%H%M")
AccontID=${1}
s3_AccountID=${2}
AWS_DEFAULT_REGION=${3} ## 3rd Argument is the Account Default Region is diff than the CLI server
csvfile=/tmp/cw-${AccontID}-${NOW}.csv
#
## Reset Env variables
reset_env () {
unset AWS_SESSION_TOKEN
unset AWS_DEFAULT_REGION
unset AWS_SECRET_ACCESS_KEY
unset AWS_ACCESS_KEY_ID
} #end of reset_env
## Set Env function
assume_role () {
AccontID=${1}
source </path_to_source_env_file/filename> ${AccontID}
}
# Function assume_role ends
assume_role ${AccontID}
if [[ ! -z "$3" ]]; then
AWS_DEFAULT_REGION='us-east-2'
fi
#
## Generate CSV file
python <path_of_the_script>/collect_cw_metrics.py ${AccontID} ${csvfile}
##
## Upload generated CSV file to S3
reset_env
assume_role ${s3_AccountID}
echo ${csvfile}
echo "Uploading data file to S3...."
aws s3 cp ${csvfile} <Bucket_Name>
reset_env
Main python Script – collect_cw_metrics.py
#!/usr/bin/python
# To Correct indent in the code - autopep8 cw1.py
import sys
import boto3
import logging
import pandas as pd
import datetime
from datetime import datetime
from datetime import timedelta
AccountID = str(sys.argv[1])
csvfile = str(sys.argv[2])
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# define the connection
client = boto3.client('ec2')
ec2 = boto3.resource('ec2')
cw = boto3.client('cloudwatch')
# Function to get instance Name
def get_instance_name(fid):
ec2instance = ec2.Instance(fid)
instancename = ''
for tags in ec2instance.tags:
if tags["Key"] == 'Name':
instancename = tags["Value"]
return instancename
# Function to get instance ID (mandatory for Custom memory Datapoints)
def get_instance_imageID(fid):
rsp = client.describe_instances(InstanceIds=[fid])
for resv in rsp['Reservations']:
v_ImageID = resv['Instances'][0]['ImageId']
return v_ImageID
# Function to get instance type (mandatory for Custom memory Datapoints)
def get_instance_Instype(fid):
rsp = client.describe_instances(InstanceIds=[fid])
for resv in rsp['Reservations']:
v_InstanceType = resv['Instances'][0]['InstanceType']
return v_InstanceType
# all running EC2 instances.
filters = [{
'Name': 'instance-state-name',
'Values': ['running']
}
]
# filter the instances
instances = ec2.instances.filter(Filters=filters)
# locate all running instances
RunningInstances = [instance.id for instance in instances]
# print(RunningInstances)
dnow = datetime.now()
cwdatapointnewlist = []
for instance in instances:
ec2_name = get_instance_name(instance.id)
imageid = get_instance_imageID(instance.id)
instancetype = get_instance_Instype(instance.id)
cw_response = cw.get_metric_statistics(
Namespace='AWS/EC2',
MetricName='CPUUtilization',
Dimensions=[
{
'Name': 'InstanceId',
'Value': instance.id
},
],
StartTime=dnow+timedelta(hours=-1),
EndTime=dnow,
Period=300,
Statistics=['Average', 'Minimum', 'Maximum']
)
cw_response_mem = cw.get_metric_statistics(
Namespace='CWAgent',
MetricName='mem_used_percent',
Dimensions=[
{
'Name': 'InstanceId',
'Value': instance.id
},
{
'Name': 'ImageId',
'Value': imageid
},
{
'Name': 'InstanceType',
'Value': instancetype
},
],
StartTime=dnow+timedelta(hours=-1),
EndTime=dnow,
Period=300,
Statistics=['Average', 'Minimum', 'Maximum']
)
cwdatapoints = cw_response['Datapoints']
label_CPU = cw_response['Label']
for item in cwdatapoints:
item.update({"Label": label_CPU})
cwdatapoints_mem = cw_response_mem['Datapoints']
label_mem = cw_response_mem['Label']
for item in cwdatapoints_mem:
item.update({"Label": label_mem})
# Add memory datapoints to CPUUtilization Datapoints
cwdatapoints.extend(cwdatapoints_mem)
for cwdatapoint in cwdatapoints:
timestampStr = cwdatapoint['Timestamp'].strftime(
"%d-%b-%Y %H:%M:%S.%f")
cwdatapoint['Timestamp'] = timestampStr
cwdatapoint.update({'Instance Name': ec2_name})
cwdatapoint.update({'Instance ID': instance.id})
cwdatapointnewlist.append(cwdatapoint)
df = pd.DataFrame(cwdatapointnewlist)
df.to_csv(csvfile, header=False, index=False)
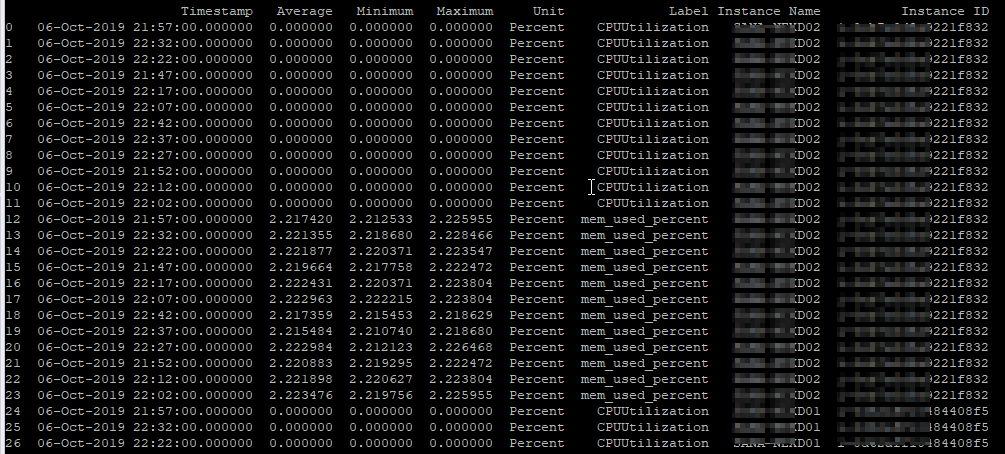
Sample Flat file (CSV format) is as shown below.

Leave a comment